Section:
New Results
ImaGINator: Conditional Spatio-Temporal GAN for Video
Generation
Participants :
Yaohui Wang, Antitza Dantcheva, Piotr Bilinski [University of Warsaw] , François Brémond.
keywords: GANs, Video Generation
Generating human videos based on single images entails the challenging simultaneous generation of realistic and visual appealing appearance and motion.
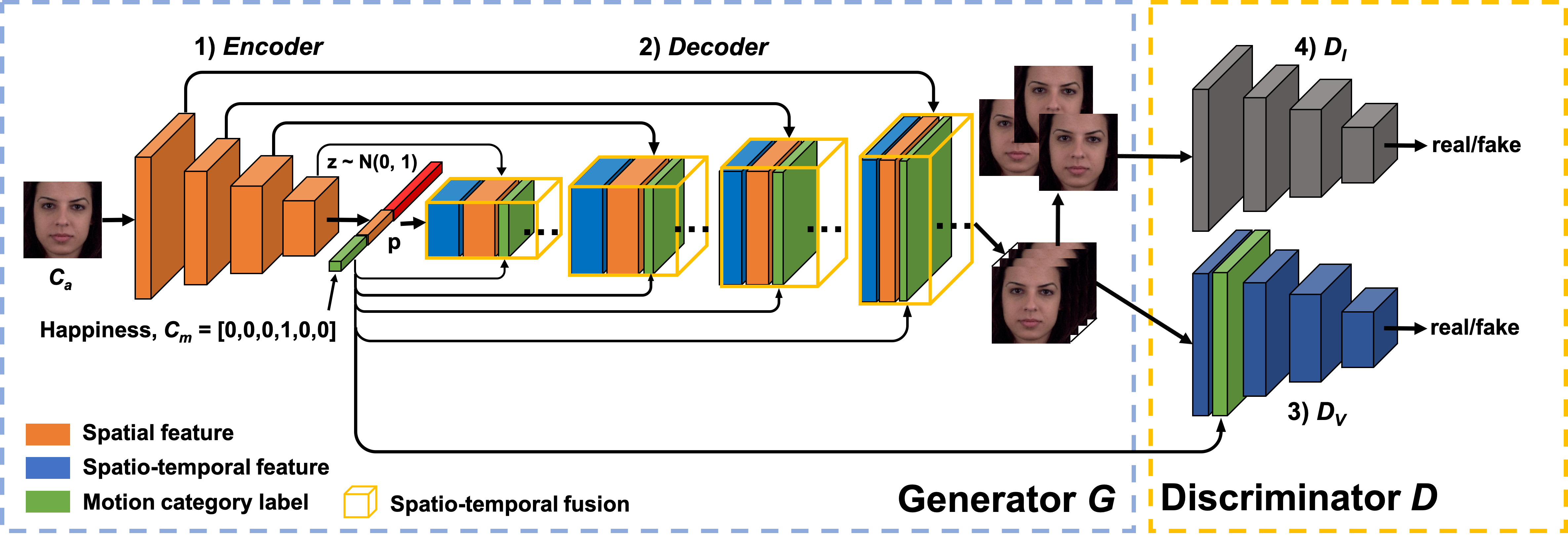
In this context, we propose a novel conditional GAN architecture, namely ImaGINator [35] (see
Figure 11), which given a single image, a condition (label of a facial expression
or action) and noise, decomposes appearance and motion in both latent and high level feature
spaces, generating realistic videos. This is achieved by (i) a novel spatio-temporal fusion
scheme, which generates dynamic motion, while retaining appearance throughout the full video
sequence by transmitting appearance (originating from the single image) through all layers
of the network. In addition, we propose (ii) a novel transposed (1+2)D convolution,
factorizing the transposed 3D convolutional filters into separate transposed temporal and
spatial components, which yields significantly gains in video quality and speed. We
extensively evaluate our approach on the facial expression datasets MUG and UvA-NEMO, as
well as on the action datasets NATOPS and Weizmann. We show that our approach achieves
significantly better quantitative and qualitative results than the state-of-the-art (see
Table 1).
Figure
11. Overview of the proposed ImaGINator. In the
Generator, the Encoder firstly encodes an input image into a single vector . Then, the Decoder produces a video based on a motion and a random vector . By using spatio-temporal fusion, low level spatial feature maps from the Encoder are directly concatenated into the Decoder. While discriminates whether the generated images contain an authentic appearance, additionally determines whether the generated videos contain an authentic motion.
|
|
Table
1. Evaluation of VGAN, MoCoGAN and proposed ImaGINator with respect to image quality (SSIM/PSNR) and video quality (FID).
|
MUG
|
NATOPS
|
|
SSIM/PSNR FID |
SSIM/PSNR FID |
| VGAN |
0.28/14.54 74.72 |
0.72/20.09 167.71 |
| MoCoGAN |
0.58/18.16 45.46 |
0.74/21.82 49.46 |
| ImaGINator |
0.75/22.63 29.02 |
0.88/27.39 26.86 |
|
Weizmann
|
UvA-NEMO
|
|
SSIM/PSNR FID |
SSIM/PSNR FID |
| VGAN |
0.29/15.78 127.31 |
0.21/13.43 30.01 |
| MoCoGAN |
0.42/17.58 116.08 |
0.45/16.58 29.81 |
| ImaGINator |
0.73/19.67 99.80 |
0.66/20.04 16.16 |